
La première partie du tutorial a montré le principe général d'extraction des oscillations EXAFS et d'ajustement d'un modèle théorique à ces oscillations expérimentales. Cette étude a été faite dans le cadre d'un seul fichier expérimental.
En pratique, on dispose souvent de plusieurs enregistrements pour le même composé. Cette partie du tutorial montre comment utiliser LASE pour tirer parti de ces diverses répétitions afin d'estimer la précision que l'on peut attendre sur les valeurs obtenues à l'issue de l'ajustement. Cette estimation se fait à l'aide d'un modèle statistique qui repose sur la réalisation de moyennes. Ce tutorial sera donc articulé de la façon suivante :
Habituellement, on est confronté pour le traitement des divers spectres à l'alternative suivante : soit on fait la moyenne dès le début, en ce cas il n'y a qu'une seule extraction à faire mais l'estimation de l'erreur statistique est perdue, soit on fait d'abord les extractions puis la moyenne, ce qui permet de conserver l'estimation de l'erreur mais multiplie le travail à effectuer.
Avec le modèle statistique intégré à LASE, il est possible de profiter des avantages des deux méthodes : on peut ne faire qu'une seule extraction, sur le spectre moyen, sans perdre l'information sur les erreurs statistiques même après filtrage par transformée de Fourier.
Dans certains cas, il n'est pas possible de faire les moyennes directement et l'on doit alors obligatoirement traiter chaque spectre individuellement. LASE dispose d'options qui permettent d'automatiser ce traitement, le rendant ainsi moins fastidieux.
Pour moyenner divers spectres, il faut avoir plusieurs spectres à disposition, donc charger plusieurs spectres expérimentaux. Ceci se fait très simplement, en sélectionnant tous les fichiers que l'on souhaite traiter dans le sélecteur de fichiers, en une seule fois. Tous seront alors chargés de la même façon, en fonction des paramètres définis dans la boîte de dialogue d'extraction des graphes.
Une fois ces spectres chargés, il est nécessaire de les comparer de façon à éliminer d'éventuels spectres aberrants (à cause d'une coupure de faisceau, par exemple) et à vérifier qu'il est légitime de faire les moyennes, c'est-à-dire que tous les spectres sont bien superposables « au bruit près ». Cette vérification peut se faire simplement en superposant les graphes, à l'aide de l'option Tracer... du menu Affichage.
Pour faciliter cette comparaison, il est possible d'assigner à chaque graphe une couleur, ainsi que de choisir quels graphes sont affichés sur cette superposition. Ce paramétrage se fait au niveau de la liste des graphes.
Si tous les spectres sont effectivement superposables, on peut réaliser directement les moyennes. Pour cela, il faut utiliser l'option Barres d'erreur du menu Erreurs, qui affiche la boîte de dialogue suivante :
La partie supérieure permet de sélectionner les graphes à moyenner, la partie intermédiaire permet de contrôler la façon dont est estiméé le spectre moyen.
Pour ajouter un spectre dans la liste des graphes à moyenner, utilisez le bouton Ajouter spectre puis sélectionnez le spectre choisi dans le sélecteur de graphes qui apparaît alors (fig. ci-dessous).
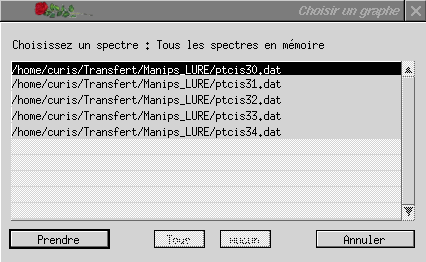
Si un graphe a déjà été indiqué, il est possible d'ajouter tous les graphes du même type en une fois, à l'aide de l'option Tout ajouter. Il est aussi possible d'ôter un graphe de la liste en le sélectionnant, puis en choisissant l'option Enlever spectre.
Pour davantage d'informations sur les options à propos du Traitement des Y ou du Traitement des X, reportez-vous à la notice détaillée.
Quand la liste des spectres est prête, le calcul de la moyenne est effectué en utilisant le bouton Calculer. Le spectre moyen créé sera affecté de barres d'erreur et portera le nom indiqué en bas de la boîte de dialogue (avec le caractère # remplacé par le nombre de spectres utilisé dans le calcul).
Ce spectre moyen peut ensuite être traité exactement de la même façon qu'un spectre classique, tel que cela a été décrit dans la première partie. Les barres d'erreur seront automatiquement adaptées à condition de bien fermer les différentes fenêtres dans l'ordre.
Il arrive que les spectres expérimentaux ne soient pas exactement superposables, mais puissent le devenir après un traitement simple, comme une extraction partielle. Une fois ce traitement effectué, l'estimation des moyennes se fait comme il a été décrit ci-dessus ; nous allons voir dans cette partie deux types de traitement et la façon de les réaliser de façon optimale dans LASE.
Cette méthode est efficace lorsque les spectres sont identiques, à
un léger décalage près, comme le montre la figure ci-dessous (qui
représente un agrandissement des oscillations après-seuil) :

Dans ce cas-là, la simple soustraction du fond continu permet de corriger cet effet, à condition de bien optimiser cette étape pour chaque spectre. Pour faciliter cette optimisation, le protocole suivant peut être utilisé dans LASE :
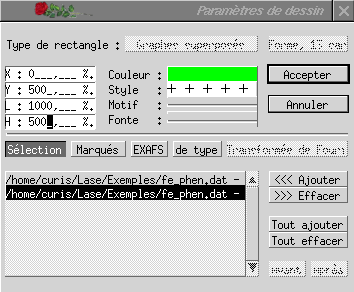
Les dimensions de la région occupée sont indiquées en haut, à gauche, en pour-milles. Si l'on veut diviser en deux, verticalement, la fenêtre de superposition, il suffit donc d'entrer 500 comme largeur.
On peut alors créer une seconde zone de dessin, en utilisant l'option Nouveau rectangle du même menu. Il apparaît la même boîte de dialogue que précédemment ; en indiquant 500 pour X et pour la largeur, on obtient alors deux zones de dessin identiques dans la fenêtre de superpositions.
En réalisant un agrandissement dans celle de droite, on arrive alors à une représentation semblable à celle présentée sur la figure ci-dessous :

Cette méthode est cependant fastidieuse quand le nombre de spectres devient grand. Aussi, LASE peut-il automatiser dans certains cas ces opérations, à condition que tous les spectres bruts soient dans la même série : lorsque l'on ferme la fenêtre permettant d'ôter le fond continu, il demande si le traitement doit être fait sur le seul spectre sélectionné, ou sur tous ceux (de même type) de la série (figure ci-dessous, à gauche).
 |
 |
Si l'on demande le traitement de toute la série, il demande alors comment adapter le traitement aux autres spectres (boîte d'alerte de droite, ci-dessus). En général, Ajuster donne les meilleurs résultats et correspond au protocole présenté ci-dessus. Pour plus de détails sur les différentes méthodes, voyez ici.
Lorsque l'on travaille avec des spectres enregistrés en fluorescence, un autre type de différence peut apparaître d'un spectre à l'autre : une variation de la hauteur de seuil. La méthode précédente n'est donc pas applicable. Pour pouvoir réaliser les moyennes, il est plutôt souhaitable de normaliser au préalable tous les spectres, de façon à ce qu'ils aient tous la même hauteur de seuil.
Pour réaliser cette normalisation, il faut utiliser l'option Normaliser du menu Absorption. Il apparaît alors la fenêtre suivante, qui permet de contrôler cette normalisation :

La courbe bleue représente un modèle de l'absorption atomique en l'absence de voisins ; son intersection avec le seuil (matérialisée par le trait rouge) correspond donc à une hauteur de seuil unitaire. Le trait rouge peut être placé à la souris (clic gauche) ; la modélisation du fonc continu est identique à celle de la première étape de l'extraction des oscillations EXAFS.
Lorsque le premier spectre a été normalisé, il est possible de l'utiliser comme référence pour contrôler la normalisation des spectres suivants. Pour cela, cliquez sur le bouton Ref : et choisissez le spectre dans le sélecteur qui apparaît alors. Le graphe indiqué apparaît en gris foncé dans la fenêtre, à la même échelle que le spectre traité après normalisation dans les conditions indiquées. Il est ainsi possible de trouver les conditions de normalisation qui permettent une superposition optimale des spectres.
Les méthodes précédentes ne conduisent pas toujours à des résultats permettant de réaliser la moyenne des spectres directement. Il est alors nécessaire de réaliser l'extraction des oscillations indépendamment pour chaque spectre. Il est bien sûr possible de le faire, pour chacun, en reprenant la procédure décrite dans la première partie de ce tutorial. Toutefois, cela devient vite fastidieux et il s'avère que, dans la plupart des cas, conserver les mêmes paramètres d'extraction pour tous les spectres conduit à de bons résultats. LASE permet donc de reproduire une extraction des oscillations directement.
Pour cela, il faut utiliser l'option Reproduire l'extraction du menu EXAFS. Il apparaît alors la boîte de dialogue suivante, qui permet de paramétrer en une fois toute l'extraction des oscillations :

Lorsqu'une extraction a été réalisée suivant la procédure « habituelle », ses paramètres sont automatiquement transmis à cette boîte de dialogue.
En général, la troisième étape est plus délicate à automatiser, car la valeur optimale du paramètre varie beaucoup d'un spectre à l'autre, aussi par défaut cette étape doit être recommencée à chaque fois. Toutefois, il est possible de sauter cette étape ou de l'automatiser aussi, grâce, respectivement, aux boutons Passer et Fixe.
De la même façon, il est possible de reproduire le calcul de la transformée de Fourier, directe ou inverse, grâce à l'option Reproduire le filtrage du menu Filtrer, qui permet de paramétrer cette reproduction grâce à la boîte de dialogue suivante :

Là encore, les paramètres utilisés lors d'un calcul par la méthode « habituelle » sont automatiquement transmis à cette boîte de dialogue.
Lorsque l'on ajuste un modèle structural aux données expérimentales, on obtient un jeu de valeurs pour ce modèle --- par exemple, la distance entre l'atome absorbeur et ses plus proches voisins. Toutefois, ajuster le même modèle, dans les mêmes conditions, sur un autre spectre expérimental enregistré sur le même échantillon aurait conduit à des résultats légèrement différents,du fait des incertitudes (statistiques ici). Comment estimer l'importance de ces fluctuations, c'est-à-dire la précision de la détermination des valeurs ?
Comme l'origine de ces fluctuations est d'origine statistique, correspondant au bruit sur les données expérimentales, il faut disposer d'une estimation de ce bruit : c'est le cas, dans LASE, grâce aux barres d'erreur qui sont obtenues lors du calcul des moyennes (tel que nous venons de le voir) et sont conservées au travers de chaque étape du traitement. Il reste à relier ces barres d'erreur expérimentales à l'incertitude sur les paramètres. Deux méthodes sont disponibles pour cela, dans LASE. Toutes deux reposent sur un modèle statistique de l'estimation par la méthode des moindres carrés, aussi allons-nous commencer par en rappeler les principes et le vocabulaire.
On essaye de reproduire un spectre expérimental, khi(k), à l'aide d'un modèle théorique khith(k), qui dépend de paramètres variables a1,..., aq que l'on cherche à estimer. Ces paramètres sont cherchés de façon à minimiser la distance entre la courbe expérimentale et son modèle théorique, ce qui revient à minimiser la somme
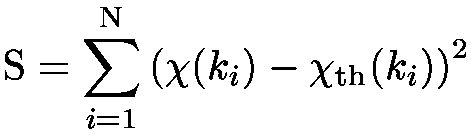
Différents enregistrements du spectre expérimental conduiront, à cause du bruit, à différentes valeurs des paramètres. Pour tenir compte de cela, chaque paramètre est considéré comme une variable aléatoire ; l'ensemble de ces variables aléatoire forme un vecteur aléatoire à q dimensions. Ce vecteur est caractérisé par son espérance (vecteur moyen) et sa matrice de covariance (ou, équivalemment, sa matrice de corrélation).
Connaître ces deux grandeurs donne toute l'information cherchée : le vecteur moyen donne les valeurs théoriques, la diagonale de la matrice de covariance l'incertitude sur ces paramètres et les termes hors-diagonale les corrélations entre les divers paramètres, cest-à-dire l'influence des variations d'un paramètre sur les valeurs obtenues pour les autres paramètres. Tout le problème est donc d'accéder à cette matrice de covariance.
Cette méthode correspond à la technique la plus fréquemment utilisée dans les procédure d'analyse en spectroscopie d'absorption des rayons X. Elle relie la matrice de covariance à la matrice des dérivées secondes de la fonction S(a1,..., aq).
Cette méthode peut être utilisée, à la fin d'un ajustement (la fenêtre d'ajustement étant toujours ouverte) à l'aide de l'option Matrice de corrélation du menu Couches. Il convient néanmoins de noter que son utilisation repose sur un grand nombre d'hypothèses. En particulier, un tel calcul n'a de sens que si l'on a utilisé un ajustement par les moindres carrés en tenant compte des barres d'erreur (bouton Barres d'erreur actif dans les paramètres généraux de l'ajustement).
Dans le cas général, la méthode précédente n'est pas toujours applicable. La méthode de Monte-Carlo repose sur un principe qui permet de s'affranchir des hypothèses de la méthode précédente.
Puisque l'origine des fluctuations est la variation du spectre expérimental d'un enregistrement à l'autre, l'idée est de générer de pseudo-spectres expérimentaux à partir du spectre moyen et des incertitudes de ce spectre. Chacun de ces spectres sera alors confronté au modèle théorique, donnant une nouvelle valeur des paramètres ajustés. Si l'on reproduit ce procédé n fois, on obtient n valeurs pour chaque paramètre, auxquelles on peut appliquer les outils classiques de statistique pour en déduire la valeur moyenne, la variance,...
Pour réaliser une simulation Monte-Carlo dans LASE, il faut appeler l'option Méthode de Monte-Carlo du menu Validité, en mode ajustements. Il apparaît alors une boîte de dialogue qui permet de définir le nombre de tirages à effectuer et les grandeurs qui doivent être automatiquement calculées en fin de simulation :
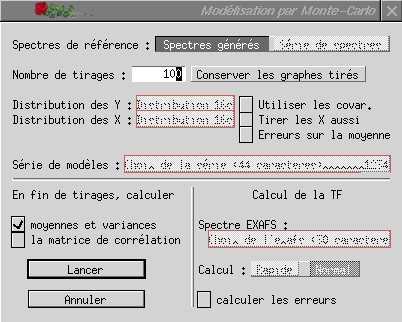
En général, entre 100 et 1000 tirages permettent d'avoir une très bonne estimation des valeurs cherchées tout en ne demandant pas trop de temps de calcul --- cette méthode étant très coûteuse en temps. À l'issue du calcul, un graphe est créé pour chaque paramètre ajustable, contenant toutes les valeurs obtenues au cours de chaque tirage et qu'il est donc possible d'analyser avec les outils statistiques de LASE ou, via un export au format ASCII, de tout autre logiciel d'analyse statistique.
LASE propose de quelques options pour faciliter l'analyse des résultats obtenus par la méthode de Monte-Carlo. Ces options sont brièvement présentées ici.
Pour obtenir la valeur moyenne d'une série de valeurs et la variance (déviation standard), utiliser l'option Moyenne & Variance du menu Erreurs. Une boîte d'alerte affiche l'estimation de la moyenne et de la variance ; dans le terminal sont indiqués en plus un intervalle de confiance à 95% pour la moyenne, les valeurs extrêmes de la série et son étendue, la médiane et l'écart absolu moyen.
Pour pouvoir établir des intervalles de confiance assortis d'une probabilité, il est nécessaire de connaître la distribution à l'origine de la répartition des valeurs observées. Cette distribution est souvent postulée gaussienne ; pour le vérifier, LASE permet de réaliser un test de Kolmogorov-Smirnov. Pour cela, il faut choisir l'option Kolmogorov-Smirnov du menu Erreurs, ce qui fait apparaître la boîte de dialogue suivante :

Pour le type de test évoqué, les réglages présentés conviennent et il suffit donc d'effectuer le test en cliquant sur le bouton Lancer. Le résultat est affiché dans le terminal.
Pour étudier les corrélations entre deux paramètres (et, plus généralement, entre deux séries de valeurs), il est possible d'estimer le coefficient de corrélation linéaire entre deux séries. Pour cela, utilisez l'option Corrélations du menu Erreurs, qui fait apparaître la boîte de dialogue ci-dessous :

Les deux boutons, à côté de Variable 1 et 2, permettent de choisir les deux séries de valeur à prendre en compte. Elles doivent avoir le même nombre de points.
| Partie 1 | Sommaire | Partie 3 |